Epstein Victims Sue Google, Claim AI Mode Exposed Personal Information
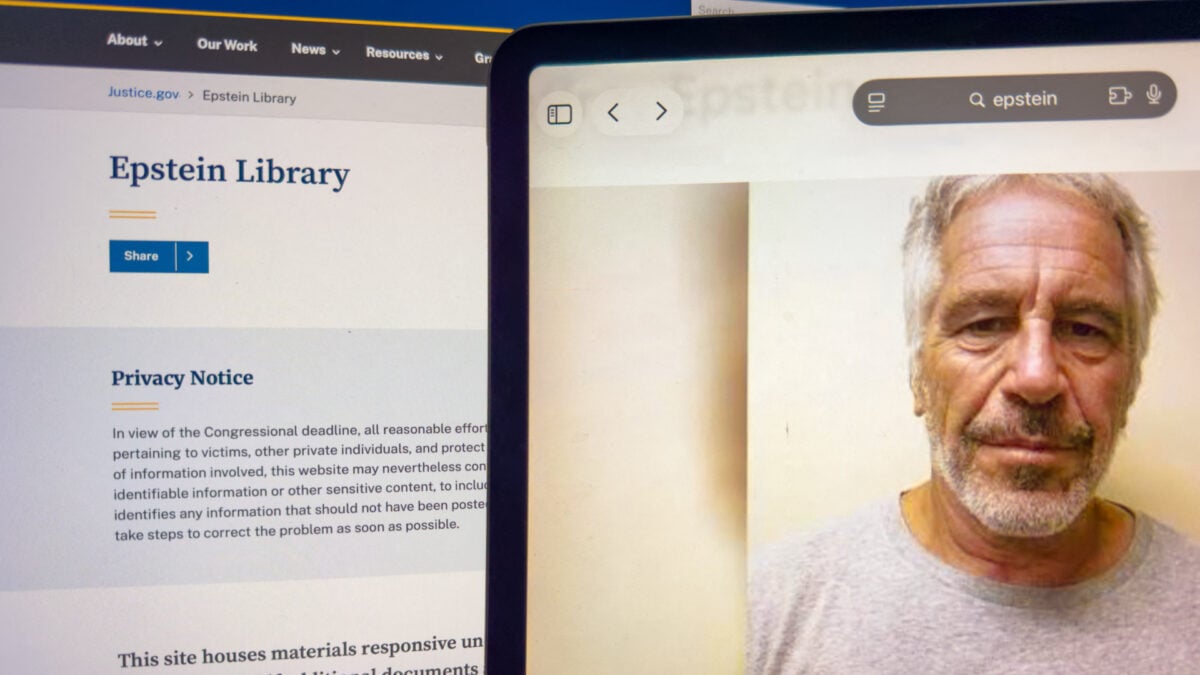
Foto: © VERONIQUE TOURNIER
More than 3 million pages of litigation documents concerning Jeffrey Epstein have become the catalyst for an unprecedented class-action lawsuit against Google. Victims of the criminal accuse the tech giant of allowing its AI Mode feature to reveal their personal data, which should have remained strictly confidential. Although the Department of Justice has been releasing evidentiary materials in batches since late last year, the anonymization process proved flawed—in many instances, the names of perpetrators were redacted, while the identities of survivors remained visible or easily readable by algorithms. For users worldwide, this case serves as a brutal warning regarding data security in the era of generative artificial intelligence. AI models, trained on vast sets of public documents, are capable of connecting facts and extracting information from improperly redacted PDF files, which in practice signifies the end of traditionally understood online privacy. This incident will force technology developers to implement significantly more rigorous security filters to prevent artificial intelligence from becoming a tool for secondary digital victimization. Google must now face questions regarding legal liability for content that its algorithms bring to light from theoretically secured source materials.
The lower limit of privacy in the era of artificial intelligence has just been drastically shifted, and Google has found itself at the very center of a scandal that could define the legal liability of LLM model creators. On Thursday, a class action lawsuit initiated by one of Jeffrey Epstein's victims was filed in court. The allegation is staggering: the AI Mode feature belonging to the Mountain View giant allegedly published and disseminated sensitive personal data of survivors who lived through the hell created by the convicted sex offender. This is not just another technical glitch regarding a celebrity's wrong birth date – it is a systemic threat to the safety of people whose identities should be protected at all costs.
An algorithmic trap for sensitive data
The mechanism of the problem lies in the way Google's artificial intelligence models process vast sets of public data. At the end of last year and the beginning of this year, the Department of Justice (DOJ) began releasing more than 3 million pages of evidence in the Epstein case. This process was the result of legislative actions, but its implementation proved tragic in its consequences. While the intention was to reveal the truth about the pedophile's network of connections, errors in the redaction of documents led to a situation where the names of some perpetrators remained hidden, while the identities of victims were de facto exposed to the public eye.
According to the lawsuit, AI Mode not only indexed this unfortunatelly shared information but actively reproduced it in responses to user queries. Google's systems allegedly brought to light, among other things, contact details of victims, which in practice means the re-victimization of individuals who have been trying to rebuild their lives in anonymity for years. The problem is that artificial intelligence does not understand ethical context – it sees data as statistical "truth" and serves it to anyone who asks the right question, ignoring the tragic social consequences.
Read also


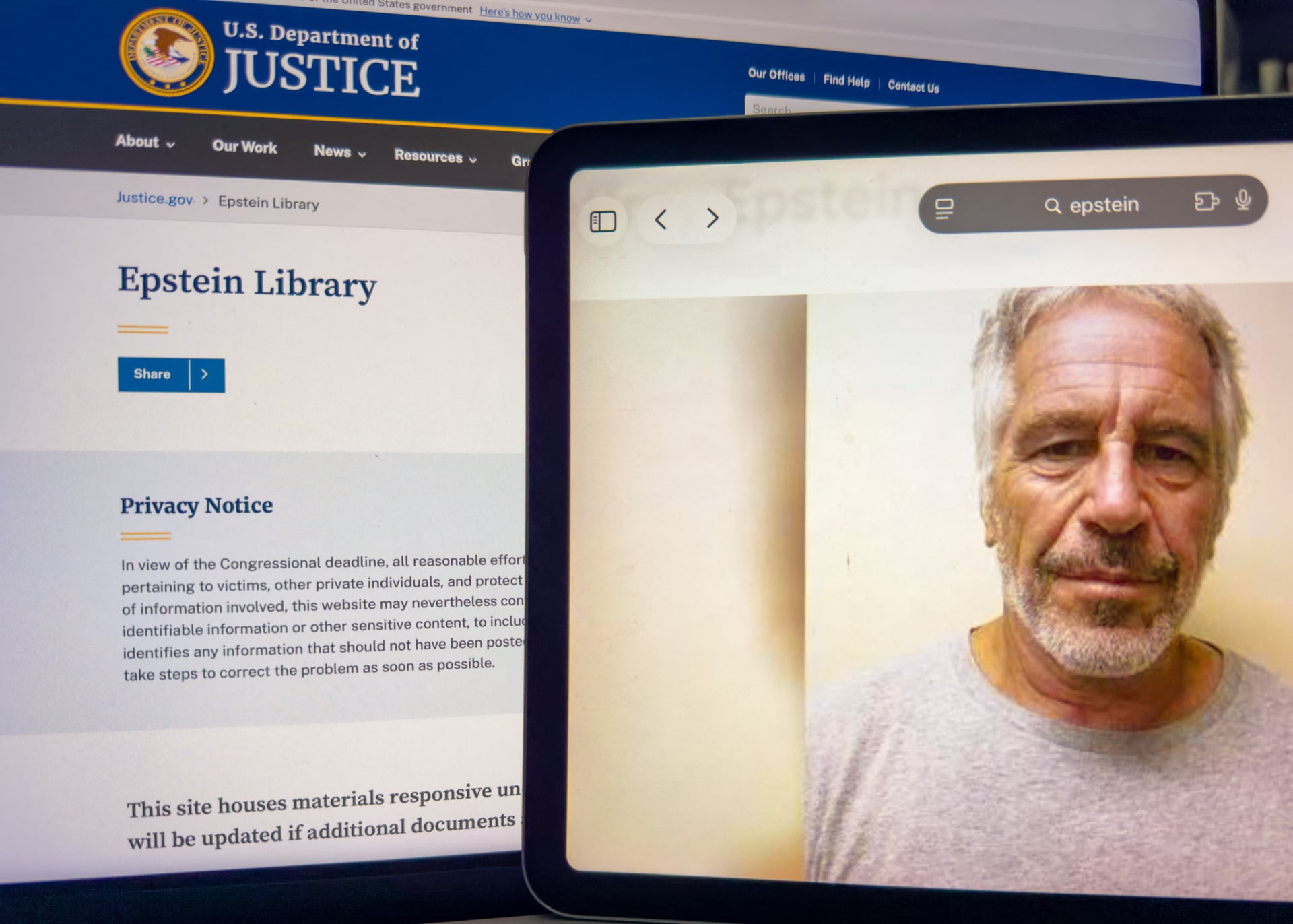
Redaction errors and blind technology
A key element of the dispute is the fact that this data came from official, albeit flawed, government documents. The DOJ released evidence in batches, and each contained so-called "improper redactions" – incorrect blacking out of text that, in the age of advanced digital tools, is trivial to bypass. Google, as an information aggregator, imported these errors into its AI ecosystem. From a technological perspective, we are dealing with the classic "garbage in, garbage out" phenomenon, but in this case, the "garbage" consists of private addresses and phone numbers of people harmed by the human trafficking system.
- 3 million pages – the scale of documentation that the AI had to process in a short time.
- AI Mode – the feature accused of lacking safety filters when serving data about victims.
- Improper redaction – an error on the DOJ's part that Google multiplied using algorithms.
For the tech industry, this is a warning signal: relying solely on the "public availability" of a source does not absolve the technology provider of responsibility for what its model generates. If AI Mode can extract a victim's specific name from millions of pages of documents and link it to their address, Google cannot hide behind the role of a "passenger." The company actively selects and presents this information in the form of clear answers, which, according to the plaintiffs' lawyers, goes beyond standard web indexing.

Legal immunity called into question
This case strikes at the foundations of legal protection enjoyed by tech giants under freedom of speech and intermediary liability laws. Traditionally, search engines were protected as long as they only linked to content created by others. However, generative artificial intelligence creates new content based on the data it possesses. If a Google model "tells" a user where an Epstein victim lives, Google becomes the publisher of that information. This is a subtle but fundamental shift in legal interpretation that could cost the company billions of dollars in damages from the class action lawsuit.
Analyzing this case, it is clear that the security mechanisms in models such as those from the Gemini series or AI Mode functions are riddled with holes. These models are trained to be helpful and informative, but their drive to provide an answer at any cost conflicts with the right to be forgotten and the protection of crime victims. Google now faces a dilemma: either drastically restrict its AI's ability to search legal and government documents, which will weaken its utility, or risk further lawsuits for large-scale violations of personal rights.
"This is not a bug in the code; it is a flaw in a product philosophy that prioritizes the speed of information delivery over human safety."
The lawsuit against Google is only the beginning of a wave of claims that will flood AI creators in the coming years. If algorithms can identify Jeffrey Epstein's victims based on incorrectly hidden data in millions of pages of documents, it means that no information that has appeared online even once – even by an official's mistake – is safe. The tech industry must understand that the "memory" of artificial intelligence is ruthless and eternal, and the lack of effective mechanisms for filtering sensitive data in real-time will turn LLM models into the most powerful tools for doxxing in history.
More from Tech



Related Articles

After court loss, RFK Jr. gives himself more power over CDC vaccine panel
Apr 6
Steven Spielberg Still Wants to Make a Horror Film ‘Someday’
Apr 6New Jersey has no right to ban Kalshi's prediction market, US appeals court rules
Apr 6