Google battles Chinese open-weights models with Gemma 4

Foto: The Register
As many as 140 languages and native support for video and audio are the key strengths of the new Gemma 4 model family, with which Google is challenging the growing dominance of Chinese giants such as Alibaba and Moonshot AI. The latest generation of open-weights from DeepMind debuts with a revolutionary licensing change—the transition to Apache 2.0 opens the door for enterprises that previously feared for their data security within closed ecosystems. The 31B variant stands out in the lineup; despite its powerful mathematical reasoning capabilities, it fits on a single consumer-grade graphics card (e.g., RTX 4090) when using 4-bit quantization. For users requiring speed, a 26B version based on the Mixture of Experts (MoE) architecture has been prepared, where only 3.8 billion parameters remain active, drastically shortening response generation time. Google has not forgotten the mobile segment—thanks to Per-Layer Embeddings (PLE) technology, smaller models with an effective size of just 2B parameters can run efficiently on smartphones and Raspberry Pi devices. The practical application of a 256,000-token context window in the larger models makes Gemma 4 a powerful tool for developers seeking local, private code assistants. This is a strategic move by Google that democratizes access to advanced AI, eliminating the need to invest in costly server infrastructure while maintaining full control over a company's intellectual property.
Google has just made its most decisive move toward the open-source sector in years. On Thursday, April 2, 2026, the Mountain View giant unveiled the Gemma 4 model family, which is intended to be a direct response to the dominance of Chinese tech giants. This new generation of open-weights models is not merely a cosmetic update – it is a comprehensive attempt to regain the trust of developers and enterprises who were increasingly looking toward solutions from Asia.
The release of Gemma 4 comes at a time when the open-source model market is being flooded by powerful systems from China. Companies such as Moonshot AI, Alibaba, and Z.AI have delivered solutions that challenge even closed models like OpenAI's GPT-5 or Anthropic's Claude in terms of performance. By releasing the fourth generation of Gemma, Google aims to offer a Western alternative that not only matches their computing power but, above all, guarantees the security of corporate data by not using it to train the giant's future proprietary systems.
Apache 2.0 and the end of restrictive licenses
The greatest revolution in Gemma 4 is not the architecture itself, but a change in the philosophy of technology sharing. Google has decided to transition to a full Apache 2.0 license. This is a step of colossal importance for the enterprise sector. Previous versions of Gemma were burdened with specific restrictions that allowed Google to terminate the agreement in case of non-compliance with terms, which created business risks for large organizations.
Read also


Thanks to Apache 2.0, companies can deploy these models without fear that "Google will pull the rug out from under them." This freedom applies not only to commercial use but also to the modification and distribution of their own versions of the model. This strategic move aims to build a loyal community around the Google ecosystem, which until now may have felt uncertain due to the "semi-open" nature of earlier iterations. In an era of fighting for AI standards, openness is becoming the strongest bargaining chip in the struggle against competitors' closed ecosystems.
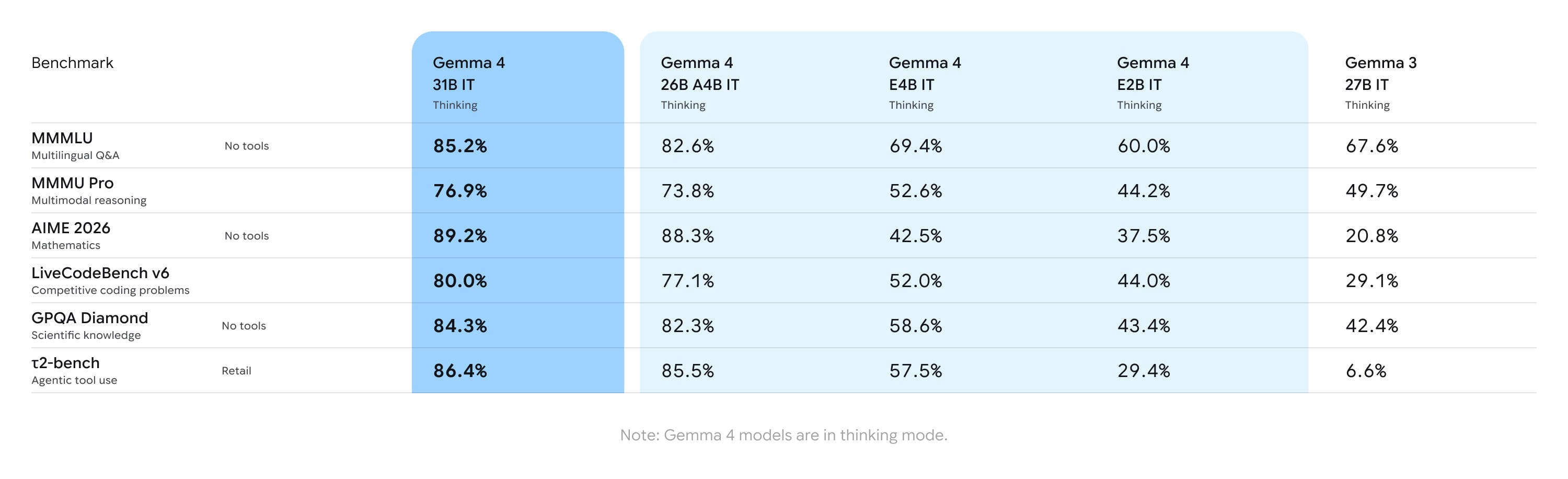
The power of 31 billion parameters on a developer's desk
The flagship model in the new offering is a variant featuring 31 billion parameters. It was designed to offer maximum quality of generated content while maintaining reasonable hardware requirements. Google has precisely balanced this model: it is powerful enough to compete with the best, but small enough not to cannibalize Google's largest paid proprietary models.
The technical specifications of this model are impressive. The 31B size model can run without quantization (in 16-bit format) on a single Nvidia H100 80 GB card. However, what will please smaller players the most is the performance after quantization. At 4-bit precision, this model fits into 24 GB of VRAM, meaning it can be run locally on consumer graphics cards such as the Nvidia RTX 4090 or AMD RX 7900 XTX. Utilizing frameworks like Llama.cpp or Ollama allows for smooth operation without the need to invest hundreds of thousands of dollars in server infrastructure.
MoE architecture and the agentic future
For applications requiring low latency, Google has prepared a 26 billion parameter variant based on the Mixture of Experts (MoE) architecture. This model features as many as 128 experts, of which only 3.8 billion parameters are activated during the generation of each individual token. This allows for a drastic acceleration of work compared to dense models of similar size, provided the user has enough VRAM to accommodate the entire structure.
Google is placing great emphasis on the "agentic" capabilities of the new model family. Gemma 4 has been optimized for advanced reasoning, which translates into better results in mathematical tasks and strict instruction-following. Key features include:
- Native function calling, allowing models to interact with external tools and APIs.
- Support for over 140 languages, making it a truly global solution.
- Multimodality: models natively handle video and audio input (especially in the E2B/E4B variants).
- A context window of 256,000 tokens for larger models, making them ideal programming assistants working on entire code repositories.
Artificial Intelligence at the edge: From smartphone to Raspberry Pi
Google has not forgotten about devices with limited computing power. The Gemma 4 family includes two smaller models optimized for "edge" hardware. They are described as models with 2 billion and 4 billion "effective" parameters. In reality, their physical sizes are 5.1 and 8 billion parameters, respectively; however, thanks to the use of an innovative per-layer embeddings (PLE) technique, their computing power requirements have been reduced by nearly half.
These miniature models maintain an impressive context window of 128,000 tokens and, surprisingly, also offer multimodality. This allows smartphones or single-board computers, such as the Raspberry Pi, to now process visual and audio data locally without sending it to the cloud. This is crucial for user privacy and for applications operating in locations with difficult network access.
Market analysis and implementation perspectives
Google's move is a clear signal that the era of closed model dominance may slowly be giving way to a hybrid approach. By making Gemma 4 available on platforms such as Hugging Face, Kaggle, and AI Edge Gallery, Google is betting on ubiquity. "Day-one" support for over a dozen frameworks, including vLLM, SGLang, and MLX (for Mac users), shows that DeepMind engineers have done their homework regarding interoperability.
In my assessment, Gemma 4 is not only an attempt to fight competition from China but, above all, an attempt to define the standard for "local AI." While OpenAI and Anthropic focus on increasingly powerful cloud models, Google is giving developers the tools to build intelligent software that runs directly on the end device. The use of the Apache 2.0 license, combined with a massive context window and multimodality, makes Gemma 4 currently the most attractive choice for creators of coding assistants and autonomous AI agents who value independence from API providers.
The introduction of the per-layer embeddings mechanism may turn out to be the "dark horse" of this premiere. If Google manages to prove that smaller models can realistically replace larger units at a fraction of the energy and CPU costs, we can expect a wave of new-generation mobile applications that will not need a constant server connection to understand the world around them through a camera or microphone. Gemma 4 is proof that in the AI arms race, optimization and licensing freedom are becoming just as important as pure computing power.
More from Industry
Broadcom agrees to expanded chip deals with Google, Anthropic
OpenAI asks California, Delaware to investigate Musk's 'anti-competitive behavior' ahead of April trial
Hope for a U.S.-Iran deal, Apple's anniversary, OpenAI's podcast deal and more in Morning Squawk
AI data center boom ‘stress tests’ insurers as private capital floods in
Related Articles

The Ridiculously Nerdy Intel Bet That Could Rake in Billions
Apr 6
Researchers didn’t want to glamorize cybercrims. So they roasted them
Apr 5
AI agents promise to 'run the business,' but who is liable if things go wrong?
Apr 5