Ofiary Epsteina pozywają Google – model AI miał ujawnić ich dane osobowe
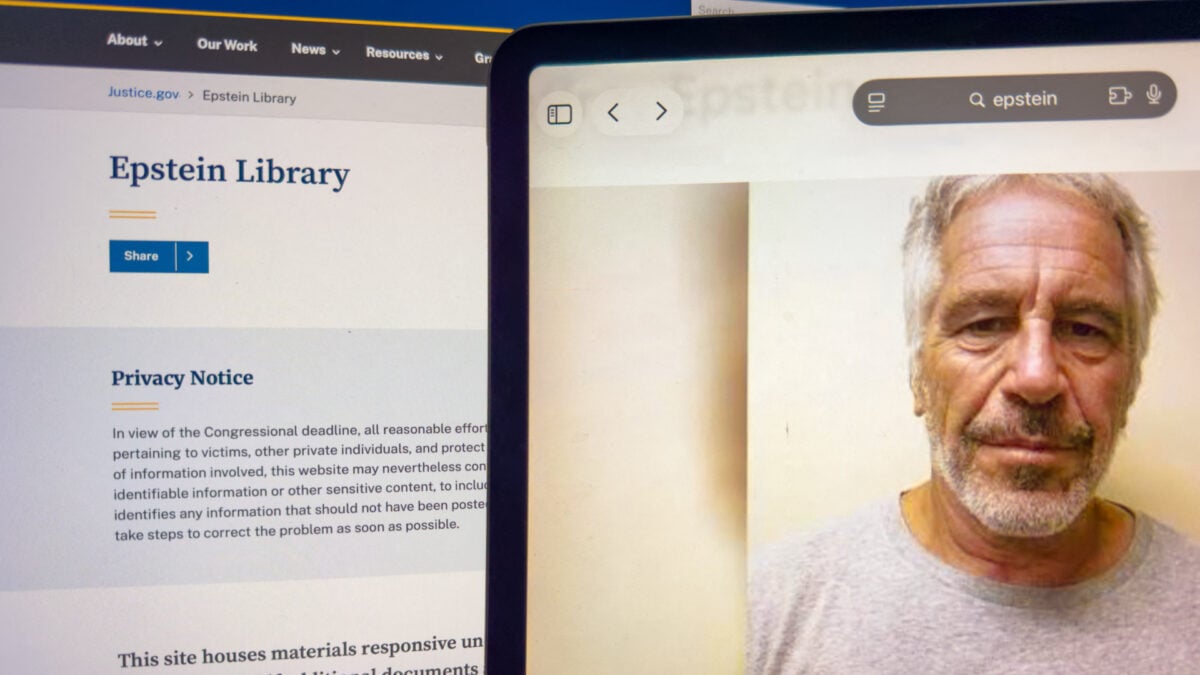
Foto: © VERONIQUE TOURNIER
Ponad 3 miliony stron dokumentów procesowych dotyczących Jeffreya Epsteina stało się zarzewiem bezprecedensowego pozwu zbiorowego przeciwko Google. Ofiary przestępcy oskarżają giganta technologicznego o to, że funkcja AI Mode ujawniła ich dane osobowe, które powinny pozostać ściśle poufne. Choć Departament Sprawiedliwości udostępniał materiały dowodowe partiami od końca ubiegłego roku, proces anonimizacji okazał się dziurawy – w wielu miejscach nazwiska sprawców zostały zamazane, podczas gdy tożsamość ocalałych pozostała widoczna lub łatwa do odczytania przez algorytmy. Dla użytkowników na całym świecie sprawa ta stanowi brutalne ostrzeżenie dotyczące bezpieczeństwa danych w erze generatywnej sztucznej inteligencji. Modele AI, trenowane na ogromnych zbiorach publicznych dokumentów, potrafią łączyć fakty i wyciągać informacje z niewłaściwie zredagowanych plików PDF, co w praktyce oznacza koniec tradycyjnie pojmowanej prywatności w sieci. Incydent ten wymusi na twórcach technologii wdrożenie znacznie bardziej rygorystycznych filtrów bezpieczeństwa, aby zapobiec sytuacji, w której sztuczna inteligencja staje się narzędziem wtórnej cyfrowej wiktymizacji. Google musi teraz zmierzyć się z pytaniem o odpowiedzialność prawną za treści, które jego algorytmy wyciągają na światło dzienne z teoretycznie zabezpieczonych materiałów źródłowych.
Dolna granica prywatności w dobie sztucznej inteligencji została właśnie drastycznie przesunięta, a Google znalazło się w samym centrum skandalu, który może zdefiniować odpowiedzialność prawną twórców modeli LLM. W czwartek do sądu wpłynął pozew zbiorowy zainicjowany przez jedną z ofiar Jeffreya Epsteina. Zarzut jest porażający: funkcja AI Mode należąca do giganta z Mountain View miała publikować i rozpowszechniać wrażliwe dane osobowe osób, które przeżyły piekło zgotowane przez skazanego przestępcę seksualnego. To nie jest kolejny błąd techniczny dotyczący błędnej daty urodzenia celebryty – to systemowe zagrożenie dla bezpieczeństwa ludzi, których tożsamość powinna być chroniona za wszelką cenę.
Algorytmiczna pułapka na dane wrażliwe
Mechanizm problemu tkwi w sposobie, w jaki modele sztucznej inteligencji od Google przetwarzają ogromne zbiory danych publicznych. Pod koniec ubiegłego roku i na początku bieżącego, Departament Sprawiedliwości (DOJ) zaczął udostępniać ponad 3 miliony stron materiału dowodowego w sprawie Epsteina. Proces ten był wynikiem działań legislacyjnych, jednak jego realizacja okazała się tragiczna w skutkach. Choć intencją było ujawnienie prawdy o siatce powiązań pedofila, błędy w redakcji dokumentów doprowadziły do sytuacji, w której nazwiska niektórych sprawców pozostały ukryte, podczas gdy tożsamość ofiar została de facto wystawiona na widok publiczny.
Według pozwu, AI Mode nie tylko zaindeksował te niefortunnie udostępnione informacje, ale aktywnie je powielał w odpowiedziach na zapytania użytkowników. Systemy Google miały wyciągać na światło dzienne m.in. dane kontaktowe ofiar, co w praktyce oznacza ponowną wiktymizację osób, które od lat próbują odbudować swoje życie w anonimowości. Problem polega na tym, że sztuczna inteligencja nie rozumie kontekstu etycznego – widzi dane jako "prawdę" statystyczną i serwuje ją każdemu, kto zada odpowiednie pytanie, ignorując tragiczne konsekwencje społeczne.
Czytaj też


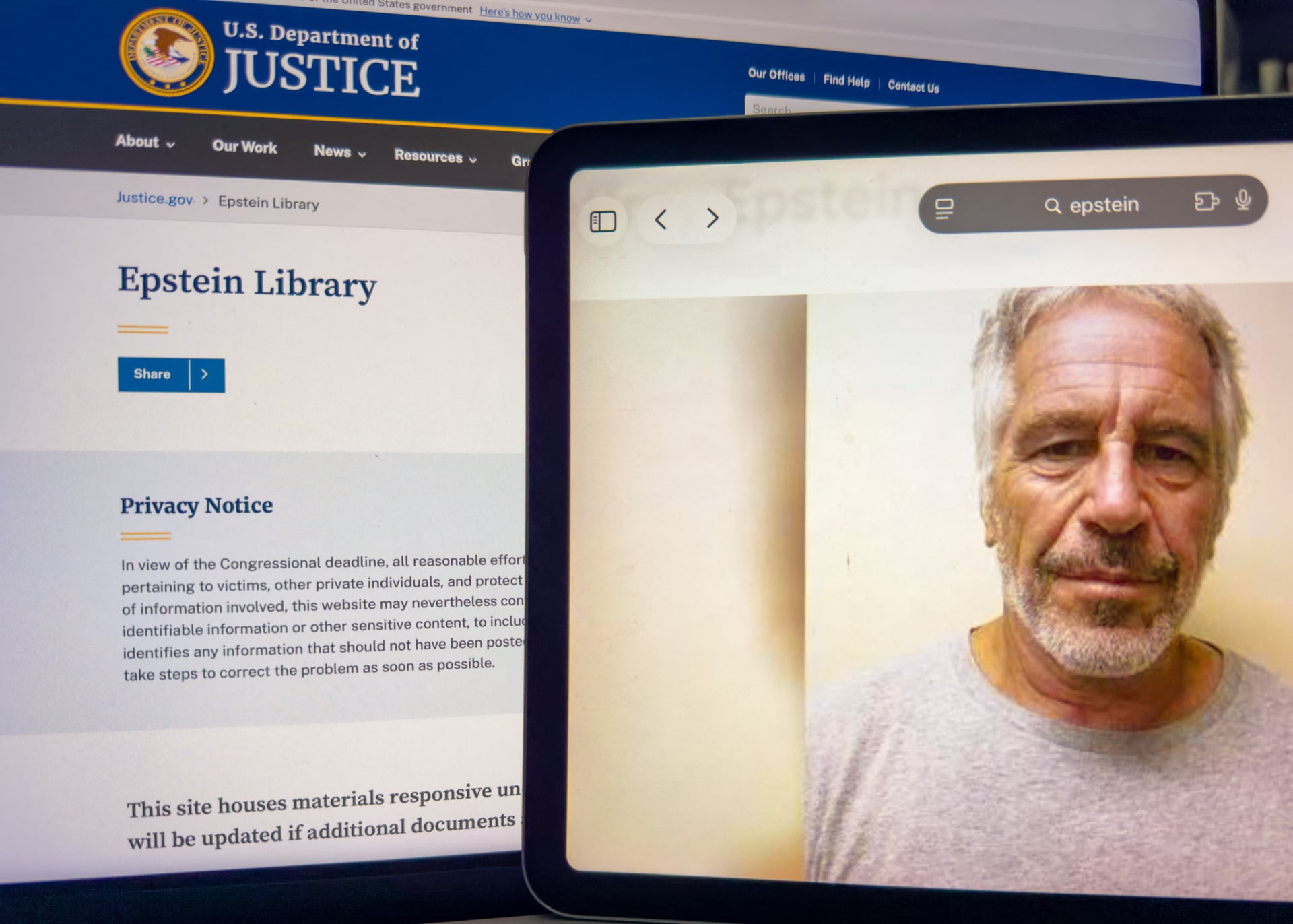
Błędy redakcyjne i ślepa technologia
Kluczowym elementem sporu jest fakt, że dane te pochodziły z oficjalnych, choć wadliwie przygotowanych dokumentów rządowych. DOJ wypuszczało dowody partiami, a każda z nich zawierała tzw. "improper redactions" – niewłaściwe zaczernienia tekstu, które w dobie zaawansowanych narzędzi cyfrowych są banalnie proste do obejścia. Google, jako agregator informacji, zaimportowało te błędy do swojego ekosystemu AI. Z perspektywy technologicznej mamy do czynienia z klasycznym zjawiskiem "garbage in, garbage out", ale w tym przypadku "śmieciami" są prywatne adresy i telefony osób skrzywdzonych przez system handlu ludźmi.
- 3 miliony stron – skala dokumentacji, którą AI musiała przetworzyć w krótkim czasie.
- AI Mode – funkcja oskarżona o brak filtrów bezpieczeństwa przy serwowaniu danych o ofiarach.
- Niewłaściwa redakcja – błąd po stronie DOJ, który Google zmultiplikowało za pomocą algorytmów.
Dla branży tech to sygnał ostrzegawczy: poleganie wyłącznie na "publicznej dostępności" źródła nie zdejmuje z dostawcy technologii odpowiedzialności za to, co jego model generuje. Jeśli AI Mode potrafi wyłuskać z milionów stron dokumentów konkretne nazwisko ofiary i powiązać je z jej adresem, to Google nie może zasłaniać się rolą "pasażera". Firma aktywnie selekcjonuje i przedstawia te informacje w formie czytelnych odpowiedzi, co według prawników strony skarżącej wykracza poza standardowe indeksowanie stron internetowych.

Prawny immunitet pod znakiem zapytania
Sprawa ta uderza w fundamenty ochrony prawnej, jaką cieszą się giganci technologiczni na mocy przepisów o wolności słowa i odpowiedzialności pośredników. Tradycyjnie wyszukiwarki były chronione, dopóki jedynie linkowały do treści stworzonych przez innych. Jednak sztuczna inteligencja generatywna tworzy nową treść na podstawie posiadanych danych. Jeśli model Google "mówi" użytkownikowi, gdzie mieszka ofiara Epsteina, to Google staje się wydawcą tej informacji. To subtelna, ale fundamentalna zmiana w interpretacji prawnej, która może kosztować firmę miliardy dolarów w ramach odszkodowań z pozwu zbiorowego.
Analizując ten przypadek, widać wyraźnie, że mechanizmy bezpieczeństwa w modelach takich jak te z serii Gemini czy funkcje AI Mode są dziurawe. Modele te są trenowane, by być pomocne i informacyjne, ale ich dążenie do udzielenia odpowiedzi za wszelką cenę stoi w sprzeczności z prawem do bycia zapomnianym oraz ochroną ofiar przestępstw. Google stoi teraz przed dylematem: albo drastycznie ograniczy zdolność swojej AI do przeszukiwania dokumentów prawnych i rządowych, co osłabi jej użyteczność, albo narazi się na kolejne procesy o naruszenie dóbr osobistych na masową skalę.
"To nie jest błąd w kodzie, to błąd w filozofii produktu, który przedkłada szybkość dostarczania informacji nad bezpieczeństwo ludzi."
Pozew przeciwko Google to dopiero początek fali roszczeń, które zaleją twórców AI w najbliższych latach. Skoro algorytmy potrafią zidentyfikować ofiary Jeffrey'a Epsteina na podstawie błędnie ukrytych danych w milionach stron dokumentów, oznacza to, że żadna informacja, która choć raz pojawiła się w sieci – nawet przez pomyłkę urzędnika – nie jest bezpieczna. Branża technologiczna musi zrozumieć, że "pamięć" sztucznej inteligencji jest bezlitosna i wieczna, a brak skutecznych mechanizmów filtrowania danych wrażliwych w czasie rzeczywistym uczyni z modeli LLM najpotężniejsze narzędzia do doxxingu w historii.
Więcej z kategorii Technologia



Podobne artykuły

Po przegranej w sądzie RFK Jr. zwiększa swoje wpływy w panelu CDC ds. szczepionek
6 kwi
Steven Spielberg wciąż planuje nakręcić horror: „Kiedyś to zrobię”
6 kwiSąd apelacyjny USA: New Jersey nie może zakazać rynków prognostycznych Kalshi
6 kwi