Google rzuca wyzwanie chińskim modelom open-weights nowym Gemma 4

Foto: The Register
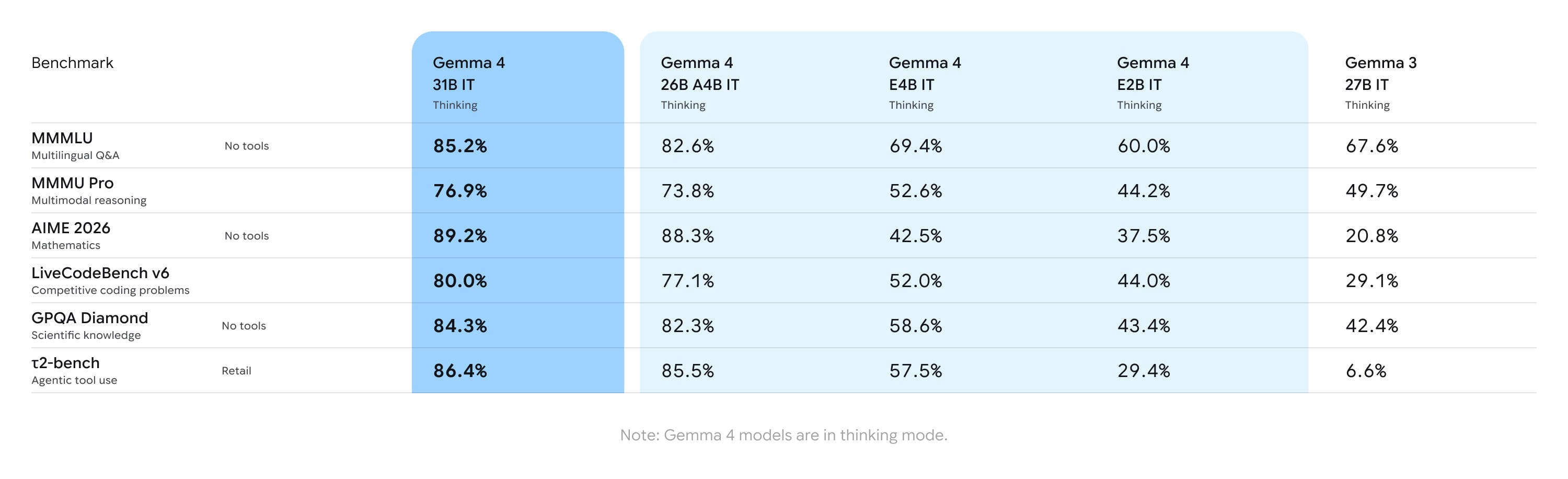
Aż 140 języków oraz natywne wsparcie dla wideo i dźwięku to kluczowe atuty nowej rodziny modeli Gemma 4, którymi Google rzuca wyzwanie rosnącej dominacji chińskich gigantów pokroju Alibaba czy Moonshot AI. Najnowsza generacja otwartych wag (open-weights) od DeepMind debiutuje z rewolucyjną zmianą licencyjną – przejście na Apache 2.0 otwiera drzwi przedsiębiorstwom, które dotąd obawiały się o bezpieczeństwo swoich danych w zamkniętych ekosystemach. W ofercie wyróżnia się wariant 31B, który mimo potężnych możliwości rozumowania matematycznego, mieści się na pojedynczej karcie graficznej klasy konsumenckiej (np. RTX 4090) przy zastosowaniu 4-bitowej kwantyzacji. Dla użytkowników wymagających szybkości przygotowano wersję 26B opartą na architekturze Mixture of Experts (MoE), gdzie aktywnych pozostaje jedynie 3,8 mld parametrów, co drastycznie skraca czas generowania odpowiedzi. Google nie zapomniało o segmencie mobile – dzięki technologii Per-Layer Embeddings (PLE), mniejsze modele o efektywnej wielkości zaledwie 2B parametrów mogą sprawnie działać na smartfonach i urządzeniach typu Raspberry Pi. Praktyczne zastosowanie okna kontekstowego o wielkości 256 tysięcy tokenów w większych modelach czyni z Gemma 4 potężne narzędzie dla programistów szukających lokalnych, prywatnych asystentów kodu. To strategiczny ruch Google, który demokratyzuje dostęp do zaawansowanego AI, eliminując konieczność inwestowania w kosztowną infrastrukturę serwerową przy jednoczesnym zachowaniu pełnej kontroli nad własnością intelektualną firmy.
Google wykonało właśnie najbardziej zdecydowany ruch w stronę sektora open-source od lat. W czwartek, 2 kwietnia 2026 roku, gigant z Mountain View zaprezentował rodzinę modeli Gemma 4, która ma stać się bezpośrednią odpowiedzią na dominację chińskich gigantów technologicznych. Nowa generacja modeli o otwartych wagach (open-weights) nie jest jedynie kosmetyczną poprawką – to kompleksowa próba odzyskania zaufania deweloperów i przedsiębiorstw, które coraz częściej spoglądały w stronę rozwiązań z Azji.
Wydanie Gemma 4 następuje w momencie, gdy rynek modeli otwartoźródłowych jest zalewany przez potężne systemy z Chin. Firmy takie jak Moonshot AI, Alibaba oraz Z.AI dostarczyły rozwiązania, które pod względem wydajności rzucają wyzwanie nawet zamkniętym modelom, takim jak GPT-5 od OpenAI czy Claude od Anthropic. Google, wypuszczając czwartą generację Gemmy, chce zaoferować zachodnią alternatywę, która nie tylko dorównuje im mocą obliczeniową, ale przede wszystkim gwarantuje bezpieczeństwo danych korporacyjnych, nie wykorzystując ich do trenowania przyszłych, własnościowych systemów giganta.
Apache 2.0 i koniec restrykcyjnych licencji
Największą rewolucją w Gemma 4 nie jest sama architektura, lecz zmiana filozofii udostępniania technologii. Google zdecydowało się na przejście na pełną licencję Apache 2.0. Jest to krok o kolosalnym znaczeniu dla sektora enterprise. Wcześniejsze wersje Gemmy były obarczone specyficznymi ograniczeniami, które pozwalały Google na rozwiązanie umowy w przypadku nieprzestrzegania regulaminu, co tworzyło ryzyko biznesowe dla dużych organizacji.
Czytaj też


Dzięki Apache 2.0 firmy mogą wdrażać te modele bez obaw, że "Google wyciągnie im dywan spod nóg". Ta swoboda dotyczy nie tylko komercyjnego wykorzystania, ale i modyfikacji oraz dystrybucji własnych wersji modelu. To strategiczne posunięcie ma na celu zbudowanie wokół ekosystemu Google lojalnej społeczności, która do tej pory mogła czuć się niepewnie z powodu "pół-otwartego" charakteru wcześniejszych iteracji. W dobie walki o standardy AI, otwartość staje się najsilniejszą kartą przetargową w walce z zamkniętymi ekosystemami konkurencji.
Potęga 31 miliardów parametrów na biurku dewelopera
Flagowym modelem w nowej ofercie jest wariant posiadający 31 miliardów parametrów. Został on zaprojektowany tak, aby oferować maksymalną jakość generowanych treści, zachowując jednocześnie rozsądne wymagania sprzętowe. Google precyzyjnie wyważyło ten model: jest on wystarczająco potężny, by konkurować z najlepszymi, ale na tyle mały, by nie kanibalizować największych, płatnych modeli własnościowych Google.
Specyfikacja techniczna tego modelu robi wrażenie. Model o rozmiarze 31B może pracować bez kwantyzacji (w formacie 16-bitowym) na pojedynczej karcie Nvidia H100 80 GB. Jednak to, co najbardziej ucieszy mniejszych graczy, to wydajność po kwantyzacji. Przy precyzji 4-bitowej, model ten mieści się w 24 GB pamięci VRAM, co oznacza, że można go uruchomić lokalnie na konsumenckich kartach graficznych, takich jak Nvidia RTX 4090 czy AMD RX 7900 XTX. Wykorzystanie frameworków takich jak Llama.cpp czy Ollama pozwala na płynną pracę bez konieczności inwestowania setek tysięcy dolarów w infrastrukturę serwerową.
Architektura MoE i agentyczna przyszłość
Dla zastosowań wymagających niskich opóźnień (low latency), Google przygotowało wariant 26 miliardów parametrów oparty na architekturze Mixture of Experts (MoE). Model ten posiada aż 128 ekspertów, z których podczas generowania każdego pojedynczego tokenu aktywowanych jest jedynie 3,8 miliarda parametrów. Pozwala to na drastyczne przyspieszenie pracy w porównaniu do modeli gęstych (dense) o podobnej wielkości, o ile użytkownik dysponuje odpowiednią ilością pamięci VRAM, by pomieścić całą strukturę.
Google kładzie ogromny nacisk na zdolności "agentyczne" nowej rodziny modeli. Gemma 4 została zoptymalizowana pod kątem zaawansowanego rozumowania, co przekłada się na lepsze wyniki w zadaniach matematycznych oraz w ścisłym podążaniu za instrukcjami (instruction-following). Kluczowe cechy to:
- Natywne wywoływanie funkcji (function calling), co pozwala modelom na interakcję z zewnętrznymi narzędziami i API.
- Wsparcie dla ponad 140 języków, co czyni ją rozwiązaniem prawdziwie globalnym.
- Multimodalność: modele natywnie radzą sobie z wejściem wideo oraz audio (szczególnie w wariantach E2B/E4B).
- Okno kontekstowe o rozmiarze 256 000 tokenów dla większych modeli, co czyni je idealnymi asystentami programowania pracującymi na całych repozytoriach kodu.
Sztuczna inteligencja na krawędzi: Od smartfona po Raspberry Pi
Google nie zapomniało o urządzeniach o ograniczonej mocy obliczeniowej. W skład rodziny Gemma 4 wchodzą dwa mniejsze modele, zoptymalizowane pod kątem sprzętu typu "edge". Są one określane jako modele o 2 miliardach i 4 miliardach "efektywnych" parametrów. W rzeczywistości ich fizyczny rozmiar to odpowiednio 5,1 i 8 miliardów parametrów, jednak dzięki zastosowaniu innowacyjnej techniki per-layer embeddings (PLE), ich zapotrzebowanie na moc obliczeniową zostało zredukowane niemal o połowę.
Te miniaturowe modele zachowują imponujące okno kontekstowe wynoszące 128 000 tokenów i, co zaskakujące, również oferują multimodalność. Dzięki temu smartfony czy komputery jednopłytkowe, takie jak Raspberry Pi, mogą teraz przetwarzać dane wizualne i dźwiękowe lokalnie, bez przesyłania ich do chmury. Jest to kluczowe dla prywatności użytkowników oraz dla aplikacji działających w miejscach o utrudnionym dostępie do sieci.
Analiza rynku i perspektywy wdrożeniowe
Ruch Google to wyraźny sygnał, że era dominacji modeli zamkniętych może powoli ustępować miejsca hybrydowemu podejściu. Udostępniając Gemma 4 na platformach takich jak Hugging Face, Kaggle czy AI Edge Gallery, Google stawia na powszechność. Wsparcie "day-one" dla kilkunastu frameworków, w tym vLLM, SGLang oraz MLX (dla użytkowników komputerów Mac), pokazuje, że inżynierowie z DeepMind odrobili lekcje z zakresu interoperacyjności.
W mojej ocenie, Gemma 4 to nie tylko próba walki z konkurencją z Chin, ale przede wszystkim próba zdefiniowania standardu dla "lokalnego AI". Podczas gdy OpenAI i Anthropic skupiają się na coraz potężniejszych modelach chmurowych, Google daje deweloperom narzędzia do budowania inteligentnego oprogramowania, które działa bezpośrednio na urządzeniu końcowym. Zastosowanie licencji Apache 2.0 w połączeniu z ogromnym oknem kontekstowym i multimodalnością sprawia, że Gemma 4 staje się obecnie najbardziej atrakcyjnym wyborem dla twórców asystentów kodowania i autonomicznych agentów AI, którzy cenią sobie niezależność od dostawców API.
Wprowadzenie mechanizmu per-layer embeddings może okazać się "czarnym koniem" tej premiery. Jeśli Google uda się udowodnić, że mniejsze modele mogą realnie zastąpić większe jednostki przy ułamku kosztów energii i procesora, czeka nas fala nowej generacji aplikacji mobilnych, które nie będą potrzebowały stałego połączenia z serwerem, by rozumieć otaczający je świat przez kamerę czy mikrofon. Gemma 4 to dowód na to, że w wyścigu zbrojeń AI, optymalizacja i wolność licencyjna stają się równie ważne, co czysta moc obliczeniowa.
Więcej z kategorii Branża
Broadcom rozszerza współpracę z Google oraz Anthropic w zakresie dostaw chipów
OpenAI prosi organy w California i Delaware o zbadanie „antykonkurencyjnych zachowań” Muska przed kwietniowym procesem
Nadzieja na układ USA-Iran, rocznica Apple i OpenAI w Morning Squawk
Boom centrów danych AI wystawia ubezpieczycieli na próbę przy napływie prywatnego kapitału
Podobne artykuły

Ryzykowny i niezwykle ambitny plan Intel, który może przynieść miliardy zysku
6 kwi
Badacze nie chcieli gloryfikować cyberprzestępców, więc postanowili ich wyśmiać
5 kwi
Agenci AI obiecują „prowadzenie biznesu”, ale kto odpowie za ich błędy?
5 kwi